几个月前,LABVIEW7I老师(高巍)向我推荐了一份PPT,其中主要讨论了性能与内存管理的问题,这是NI公司内部团队写的,因此非常珍贵。 LABVIEW对用户屏蔽了内存使用的细节,作为用户很难了解内存是如何使用的以及如何提高程序的运行性能。这份PPT是难得一见的性能与内存管理方面的 资料,所以高老师希望我能翻译其中重要的部分,介绍给大家。
对于英文资料,在翻译的同时,不可避免地会参杂一些个人的理解,如果对其中的内容有歧义,欢迎大家留言讨论。
对于英文资料,在翻译的同时,不可避免地会参杂一些个人的理解,如果对其中的内容有歧义,欢迎大家留言讨论。
性能与内存管理
目标:
- 理解LABVIEW执行系统
- 学习如果通过减少数据拷贝以及减少总的内存使用来改进性能
- 了解VI的执行特性
LABVIEW执行系统
- 执行系统是LABVIEW重要的组成部分,负责实际运行我们的代码。
- 启动自动并行机制
- 对于LABVIEW来说非常特殊---其它编程语言需要人工进行线程管理。
但是在某些情况下,我们有必要了解执行系统是如何工作的,因为这有助于我们改进程序的运行性能。
- 执行系统的工作类似一个线程池。一个任务队列和一个线程集合提取任务出队列。
- 任务(“队列元素”)就是VI代码需要执行的片段。
- 每个执行系统对应一个队列,包括UI执行系统、标准执行系统、仪器执行系统、数据采集执行系统、其它1执行系统、其它2执行系统和定时循环执行系统
LABVIEW实际拥有6个通用的执行系统,每个执行系统拥有一个独立的队列。另外,每个定时循环拥有自己独特的执行系统。
- 每个执行系统具有多个线程
- UI执行系统是个例外,它只有一个线程。
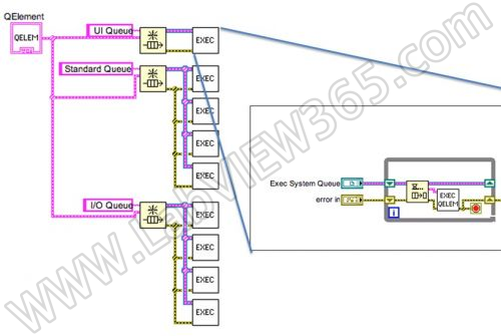
上图是LABVIEW执行系统如何工作的模型图。对于每个执行系统(上图中示意了三个执行系统),我们各自创建了一个队列。入队的数据代表了VI代码中需要执行的片段。当这个需要执行的片段准备好要运行时,LABVIEW把它放入到某个执行系统的队列中。
每个执行系统包括一个或者几个线程,这些线程中一个包括一个循环,负责把代码片段出队列并执行之。UI执行系统只拥有一个UI线程,其它执行系统可以拥有多个线程,但是共享 一个队列。当VI代码并行运行时,由执行系统的不同线程进行管理。
每个执行系统包括一个或者几个线程,这些线程中一个包括一个循环,负责把代码片段出队列并执行之。UI执行系统只拥有一个UI线程,其它执行系统可以拥有多个线程,但是共享 一个队列。当VI代码并行运行时,由执行系统的不同线程进行管理。
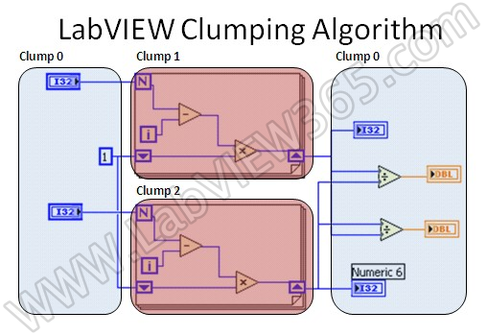
除了操作系统的抢先式多任务系统外,LABVIEW引入了协作式多任务系统。在编译过程中,LABVIEW分析VI,定位那些可以共同执行的节点 组,称作CLUMPS,每个由优先级和执行系统组成的运行数据队列结构把这些可以共同运行的CLUMPS保存在一起。当执行系统激活一个线程时,执行系统 解析这些CLUMPS并执行之。当执行系统执行完后,运行队列存入其它的符合输入条件的CLUMP进队列,这使得程序框图可以在任意的有效线程中运行。如 果程序框图包含了足够的并行机制,就可以在所有的线程中同时运行。
LABVIEW并不是对某个CLUMP分配特定的线程,在VI再次运行 时,同样的CLUMP可能被分配到不同的线程中。每个CLUMP都会产生一小段代码由LABVIEW调度。在CLUMP内部,LABVIEW不会使用并行 机制,在CLUMP之间,LABVIEW利用执行系统执行多任务。
LABVIEW并不是对某个CLUMP分配特定的线程,在VI再次运行 时,同样的CLUMP可能被分配到不同的线程中。每个CLUMP都会产生一小段代码由LABVIEW调度。在CLUMP内部,LABVIEW不会使用并行 机制,在CLUMP之间,LABVIEW利用执行系统执行多任务。
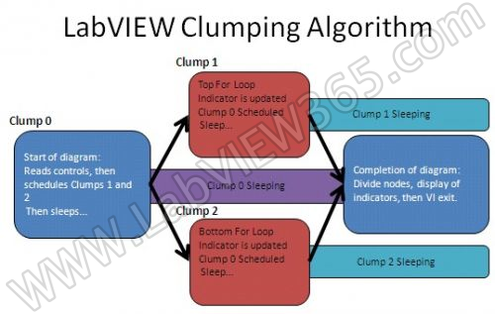
上图展示的CLUMP代表了程序框图开始到结束的过程,当执行中间两个FOR循环时,CLUMP处于“睡眠”状态。然后被“唤醒”完成VI(执行两个除法运算)。
当一个节点进入“睡眠”状态时,它把自己放入一个等待队列中,然会再返回到执行系统中。当等待结束后,它脱离等待队列,再次放入到执行队列中。
当一个节点进入“睡眠”状态时,它把自己放入一个等待队列中,然会再返回到执行系统中。当等待结束后,它脱离等待队列,再次放入到执行队列中。
首选执行系统
- 某些节点必须运行在U线程中
- 每个VI都可以指定首选的执行系统,默认情况下选择“与调用者相同”
另外,每个VI都可以选择首选的执行系统,默认情况下为“与调用者相同”,这意味着VI可以运行在任何执行系统中。
切换执行系统
- 当代码需要工作在不同于调用VI的执行系统,或者此前运行的执行系统时,就发生了执行系统的切换。
- 通常发生在与UI操作有关的代码中。
- 切换执行系统会导致运行性能的问题。需要进入睡眠状态,然后在其它执行系统 中被唤醒。切换会产生耗时。
- 避免不必要的VI代码
当一个节点需要运行,但是节点需要运行在另外的执行系统(非当前运行)中时,这会导致队列元素处于“睡眠”状态,并在其它的执行系统中被唤醒。这意 味着这段代码将停止运行,把自己放入到希望运行的那个执行系统队列中。当那个执行系统有时间时,执行系统从队列中取出元素并执行之。这种执行系统的切换需 要耗费时间,可能会引起性能的下降。
为了避免这种执行系统的切换,我们应该避免不必要的UI代码(比如服务器属性节点)。对子VI使用“与调用者相同”的执行系统可以有效地避免不必要的执行系统切换。
在下列两种情况下,我们可能会对VI使用特定的首选执行系统.
为了避免这种执行系统的切换,我们应该避免不必要的UI代码(比如服务器属性节点)。对子VI使用“与调用者相同”的执行系统可以有效地避免不必要的执行系统切换。
在下列两种情况下,我们可能会对VI使用特定的首选执行系统.
- 如 果VI内部含有必须在UI线程执行的代码,当我们使用“与调用者相同”选项时,VI执行时必须切换到UI线程,然后再返回到调用方的执行系统,以便结束子 VI时,能够继续调用方的执行系统继续运行。假如子VI运行的一个循环时,这会导致子VI内部不断反复切换执行系统,极大影响程序的性能。这种情况下,如 果对子VI选择工作在UI线程,则进入子VI之前切换到UI执行系统,在循环中一直在UI执行系统下运行,在退出之前切换到调用者的执行系统。这样执行系 统的切换只会在进入和退出前发生两次,可以极大提高程序的运行性能。
- 如果一个VI内部存在一个长时间的循环运行的任务,如控制数据采 集,我们可以设定VI工作在其它执行系统(仪器执行系统、数据采集执行系统、其它1执行系统或者其它2执行系统)。这样这些任务就不会和其它VI竞争获取 执行系统操作时间。我们需要注意,如果我们不是工作在实时操作系统中,我们还要考虑操作提供本身的调度问题。通过控制定时循环的优先级可以有效地控制我们 代码执行的优先执行次序,在实时操作体统中,定时循环的优先级更为可靠,也更加明显。
优先级
- 子VI的优先级影响执行系统中队列元素的优先级。
- 高优先级的队列元素优先出队列。
- 子VI的优先级高低设置并不影响执行系统线程自身的优先级。
子程序优先级
- 子程序优先级并非真正的优先级。
- 对于经常被调用的代码可以减少执行系统的开销。
- 强制把整个VI放在一个单独的CLUMP中。
- 阻止VI进入睡眠状态。
- 没有并行机制
- 可以被设置为“如果忙,去除子程序设置”。
- 通常不推荐使用。
子程序优先级并非真正的VI优先级。VI的优先级是通过改变队列中元素的优先级实现的,而子程序优先级是把整个VI放入在一个CLUMP中,这就保证了 VI一旦执行就不会进入睡眠状态。这意味着我们不能在子程序内部调用有可能导致进入睡眠状态的其它子VI,在VI内部也不能引发执行系统的切换。设定为 “子程序优先级”的VI在内部只能调用同样设置为“子程序优先级”的其它子Vi。“子程序优先级”的VI的代码在内部执行时都是按照次序执行,而不是并行 运行。
内嵌(内联)VI
- 首选用于替代子程序优先级
- 当主调VI编译完成后,整个设置为内嵌的子VI的全部代码插入到主调VI中。这样就不存在调用的开销了。
- 依然支持并行运行机制。
- 允许更多的编译优选项。
- 存在下列限制:不允许访问前面板,仅支持部分节点,当子VI反生变化时,强迫主调VI重新编译。
封锁线程
- 在执行调用期间,外部代码(如调用库函数、CIN节点、NET、ACTIVEX等等)会锁定线程。
- 由于C代码不使用LABVIEW队列元素,所以运行时会锁定线程。
- 等待期间,其它VI无法运行。
- 一般情况下,无法中止外部代码的操作。
LABVIEW的执行系统是基于多线程相互协作的基础上,但是其它语言编写的代码并非如此。这意味着当我们从LABVIEW中调用外部代码 时,LABVIEW只有在外部代码操作完成后才能继续线程操作。当外部代码需要等待运行权限或者其它原因进入等待状态时,当前的执行系统必须等待外部操作 代码运行结束,因此等待期间,执行系统内不会有其它VI运行。如果外部代码无法完成,经常会导致出现“重置VI”对话框。如果使用调用库函数节点调用外部 代码,则需要在配置对话框中的“回调”也选择合适的选项,避免这个问题的发生。
连线的含义
- 每一条连线都代表一个缓冲区。
- 连线分支会导致数据拷贝。
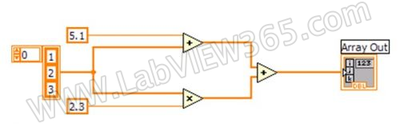
LABVIEW的数据流编程模式意味着每一条数据连线都操作着它自身的数据拷贝,在子VI内部同样也需要创建数据的拷贝。由于两个分支创建了数据拷贝,因此两个分支可以同时独立工作,不 会出现数据锁定的情况。
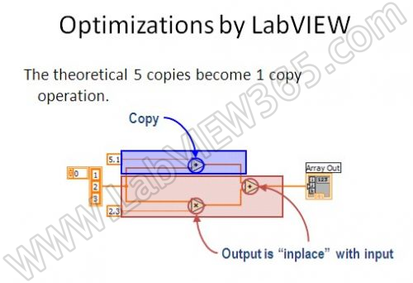
在上图的示例中,按图索骥需要5个数组的拷贝。但是实际上LABVIEW仔细分析这段代码,发现可以分为上下两个分支,分别执行加法操作和乘法操作。上面 分支中,表明的部位(+)产生一个拷贝,因为加法操作将改变输入部分的数组,对输入的数组具有破坏性。下面的分支LABVIEW进行了优化,乘法输出和加 法输出采用同地址操作,使用相同的数组。可以看出,经过LABVIEW的优化,需要5个拷贝变成了只有一个拷贝。这个优化方案是非常理想的,因为上下两个 分支都需要把数据写回数组,所以不管使用那种编程语言,都需要至少一个拷贝的过程。
 RSS Feed
RSS Feed