最近GSD论坛上的一个帖子谈到了全局变量的问题:
在保证数据不冲突的情况下可以对全局变量写操作吗?
RTRT,各位高手解释下,我在陈树学老师的宝典里看到说在程序里要避免对全局变量进行写操作。
当然可以
不行的话,要它干啥
我有一个自动化测试程序,里面有很多LabVIEW全局变量,可以读和写。是前一任离职的兄弟留下的。目前运行很正常。
关于慎用全局变量的问题,很多编程语言方面的书籍都会提及,NI论坛上有一个长达十几页的帖子专门讨论的这个问题,非常详细。
其中不仅仅涉及全局变量,还提及了许多解决问题的技巧。
下面我大概翻译一下其中重要的部分,希望有助于理解如何正确使用全局变量。帖子很长,我需要用几天的时间陆续给大家介绍。
------------------------------------------------------------------------------------------------------------------
TBOB:
不止一次地看到人们在抱怨,全局变量是罪恶之源,根本就不应该使用它们。但是我不认为这个结论是显而易见正确的。我希望能听到一次有关全局变量的严肃认真的讨论。论坛中的朋友们很多都提到了他们都正在编程中使用全局变量。
先从全局变量的有点谈起。一般来说,全局变量是公认的在各个VI之间传递数据的有效方法,比起其它方式的全局变量(个人意见)更容易管理,因为假如我们使用了一个簇作为全局数据,我们没有办法确定在何处使用了它们,可能需要自己创建一个文件记录它们使用的位置。但是全局变量则不然,通过全局变量的右键快捷菜单,我们可以很容找到引用全局变量的位置。
使用全局变量有两个不利之处,其一,引用全局变量需要创建数据的拷贝,这可能会导致潜在的竞争条件或者导致数据的丢失。其二,使用全局变量会中断数据流程。
所以,我对那些反对使用全局变量的人士提出一个问题---你们在应用全局变量时考虑了全局变量是否有效的问题了吗?
如果对全局变量只有一个写入者,而有多处读取者,您仅仅关心变量的最新写入值的情况下,您怎么能断定不能使用全局变量呢?
------------------------------------------------------------------------------------------------------------------
Darren:
全局变量在某些情况下是非常好用的。如果我有一些静态数据,这些静态数据必须在多个VI中共享,这种情况下,我会使用全局变量存储这些静态数据。(所谓静态数据就是不需要改变的数据,常量)。最常见的例子是需要给用户提示的文本字符串。如果我有一个非常复杂的GUI,需要在很多地方向用户提示文本信息。我会创建一个全局变量VI,把这些字符串创建为全局变量,并且按照字母顺序排序(通过设置TAB ORDER)。这样我们需要在程序框图中使用全局变量时,直接拖入并选择我们需要的。这种方法可以很容易使我们的应用程序本地化,因为所有的显示字符串集中在一个VI之中,而不是散布在各个VI之中,很容易集中处理。
我另外一次使用全局变量是在一个子面板应用中,因为我的子面板中的VI不需要和主VI交换信息,所以我将子面板VI中的数据写入全局变量,供应用程序其它部分读取。因为不需要同步化以及只有子面板中的VI写入数据,保证了只有一个写入者,这恰恰是全局变量的最佳工作方式。
------------------------------------------------------------------------------------------------------------------
TBOB:
很高兴能看到同人谈及如何恰当地使用全局变量,而不是简单地说完全不要使用全局变量。我们更应该强调如何恰当地使用全局变量,帮助人们了解数据竞争是如何产生的,以及如何避免竞争情况出现。
我大多数使用全局变量时,是把全局变量作为常量来使用的,比如保存一个GPIB的地址。它们一旦创建后就永远不会再次写入更改,这种情况下,绝对不会出现数据竞争的情况。或者在生产消费者模式中,生产者写入全局变量,而消费者读取全局变量。这种情况下,读的时机是非常重要的。我使消费者不断查询全局变量,是否和原来的值发生变化。换句话说,消费者在数据更新之前可能读取了两次,当然并不很理想。
对于局部变量也是如此,总有它们合适使用的场合,但是必须小心可能会导致的问题。教会人们发现问题和解决问题好于仅仅说避免使用它们。
------------------------------------------------------------------------------------------------------------------
Jasonhill:
我也经常看到要求禁止使用全局变量,在合适的条件下,使用全局变量还是非常有用的。但是程序员还是会不自觉地倾向于滥用它们,任何变量(全局变量、局部变量、LV2全局变量)在使用时需要格外小心,“连线”还是最安全的。
我非常讨厌上下或者左右堆积大量的控件,在程序框图中多达20几个层叠顺序结构中,到处散布一些全局变量或者局部变量。
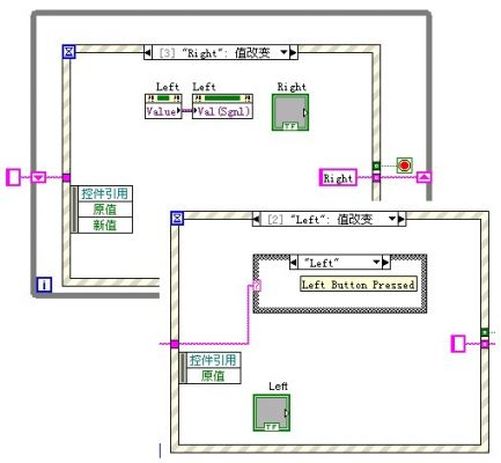
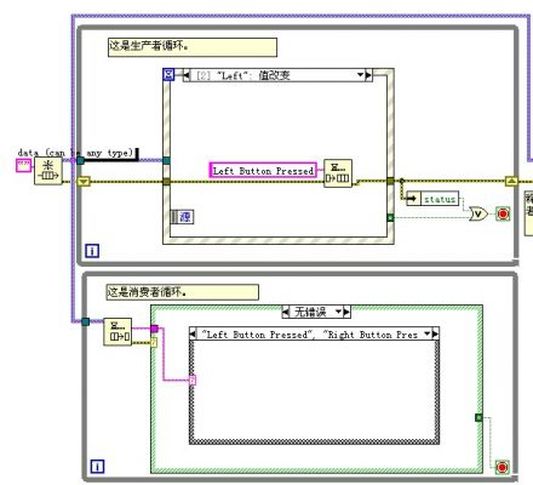
至于你提及的生产者消费者模式,我还是愿意使用队列来完成,使用队列可以使我们不需要考虑读的时机问题。
------------------------------------------------------------------------------------------------------------------
TBOB
在生产者消费者模式中,使用队列(我也倾向于使用队列,而不是变量)同样存在问题。消费者可能运行速度高于消费者,此时可能读回空数据,必须在编程中检查是否是否读回空数据。
------------------------------------------------------------------------------------------------------------------
TST:
在生产消费者模式使用队列时,我愿意使用超时的默认值-1,这意味着消费者在没有数据时不会执行一个循环,也不需要检查超时是否发生了。
------------------------------------------------------------------------------------------------------------------
TITOU:
真是个好题目!
全局变量是魔鬼吗?------我愿意这样回答:不是,只要你遵循了全局变量的工作规则。
我经常建议避免使用全局变量,但是的确在特定的场合,我还是会使用全局变量,因为使用全局变量的确非常方便。
使用但不要滥用------------------------------------------------------------------------------------------------------------------
ROBERT:
即使在基于文本的编程语言中,采用封装和抽象本身就倾向于不使用全局变量。理想的结构应该是这样的,如果函数需要一个变量,必须从函数的调用者哪里接收这个变量。尽管如此,即使在这样的编程环境中,还是需要有限度的和合理的利用全局变量。正如上面的帖子中指出的那样,一个写入者,多个读取者。亦或需要在整个程序应用,但是不需要改变的场合。
我经常采样下面的方式。在程序启动时,先运行一个配置函数或者“参数设置”函数,此时没有其它的进程工作,数据采集也尚未进行。此时为程序的其它部分创建全局变量是合理的。
------------------------------------------------------------------------------------------------------------------
KEVIN:
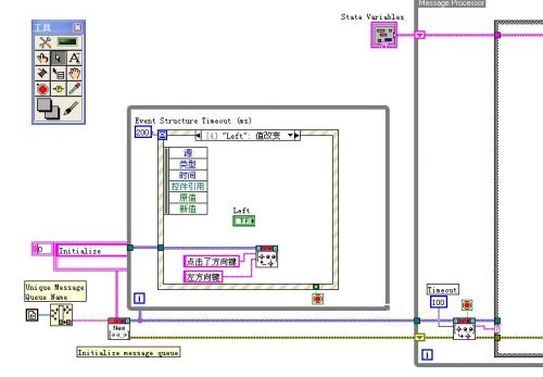
我在程序开发时,习惯于在多个消费者情况下使用“通告”。通常情况下,只有一个生产者。但是像全局变量情况,可能会有几个“潜在”的生产者。
对于使用通告,消费者可以进行选择。通告可以不管消费这是否已经消费了先前的数据,随时查询最新的数据,这类似于全局变量。通告也可以一直等待,直至有最新更新的数据,避免不断的轮询数据,加重CPU的负担,这个是全局变量无法实现的。
-----------------------------------------------------------------------------------------------------------------
BEN:
很抱歉没能早点参与这个话题的讨论。我并非求全责备,但是全局变量存在下列主要问题:
1、数据拷贝
2、利用线程
3、对于一个写入者,多个读取者,OK.但是这要求开发者必须确认只有唯一一个写入者。这对一个拥有800多个VI,有些是动态载入的情况下,是很难做到的。
4、灵活性 。如果你使用一个LV2型全局变量,需要的情况下,你可以很安全地添加新的新的写入者。在编写大型应用时,这的确是令人头疼的问题。
5、性能。LV2全局变量可以很容易重用缓存,全局变量不行。
-----------------------------------------------------------------------------------------------------------------
RAY:
我同意大家的看法。我通常用全局变量保持静态数据,比如IP地址。
-----------------------------------------------------------------------------------------------------------------
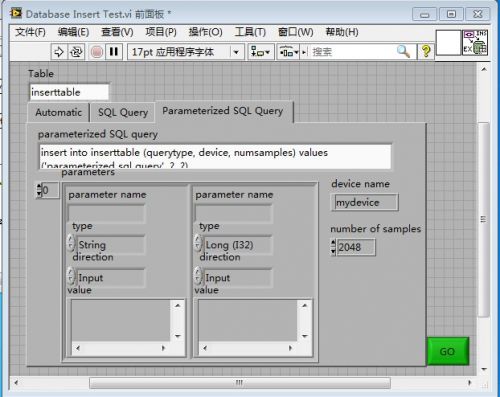




 RSS Feed
RSS Feed